ROS 2 Message Research
This article captures the research done in regards to the serialization component, including an overview of the current implementation in ROS 1 and the alternatives for ROS 2.
Authors: Dirk Thomas and Esteve Fernandez
Date Written: 2013-12
Last Modified: 2019-05
This document pre-dates the decision to build ROS 2 on top of DDS.
This is an exploration of possible message interfaces and the relation of the underlying message serialization. This paper is focused on specifying the message API and designing the integration with the serialization with performance as well as flexibility in mind. It is expected that there are one or more message serialization implementations which can be used, such as Protobuf, MessagePack and Thrift.
Background
The messages are a crucial part of ROS since they are the interface between functional components and are exposed in every userland code. A future change of this API would require a significant amount of work. So a very important goal is to make the message interface flexible enough to be future-proof.
Existing Implementations
ROS 1 messages are data objects which use member-based access to the message fields. While the message specification is not very feature rich the serializer is pretty fast. The ROS distribution contains message serializers implemented in C++, Python and Lisp. Besides that the community provided implementations for other languages, like C, Ruby, MatLab, etc.
Other existing serialization libraries provide more features and are tailored for specific needs ranging from small memory footprint over small wire protocol to low performance impact. For the usage on a small embedded device the constraints regarding the programming language and the available resources is very different from when being used on a desktop computer. Similar depending on the network connectivity the importance of the size of the wire format varies. The needs might even be different within one ROS graph but different entities.
Areas for Improvement
Future-proof API
Due to the broad domains where ROS is being (and will be) used and their different requirements and constraints we could not identify a single serialization library which matches all of them perfectly well. It is also likely that in the near future more libraries with new advantages (and disadvantages) will come up. So in order to design the message API in a future-proof manner it should not expose the serialization library used but make the actually used serialization library an implementation detail.
Serialization should be optional
With the goal to dynamically choose between the former node and nodelet style of composing a system the important the amount of scenarios where messages are actually serialized (rather than passed by reference) is likely to decrease. Therefore it would be good if no serialization library needs to be linked if the functionality is not used at all (e.g. on a self-contained product without external connections). This approach would also encourage a clean modular design.
Use existing library
In order to reduce the future maintenance effort existing libraries should be used in order not to specify and implement yet another wire protocol.
Support more features
Fixed length messages
Optional variant of a message which avoids dynamic memory allocation e.g. in real time systems. Since this use case implies severe constraints that are not optimal for scenarios where dynamic memory allocation is feasible this should not limit the solution but should be provided as an alternative implementation.
Optional fields, default values
In ROS 1, messages and services require all data members and arguments to be specified. By using optional fields and default values, we can define simpler APIs so that users' code can be more succinct and more readable. At the same time we could also provide sane values for certain APIs, such as for sensors.
Additional field types: dictionary
Dictionaries or maps are widely used in several programming languages (e.g. Python), thanks to being built-in data types. However, in order to support dictionaries in as many languages as we can, we have to take into consideration whether all languages provide mechanisms for supporting them. Certain semantics will have to be considered in the IDL, such as what datatypes can be used as keys. This feature would also imply backwards-incompatible changes to the ROS IDL.
Considerations
Member-based vs. method-based access
A message interface which utilizes member-based access to the message fields is a straightforward API. By definition each message object stores its data directly in its members which implies the lowest overhead at runtime. These fields are then serialized directly into the wire format. (This does not imply that the message is a POD - depending on the used field types it can not be mem-copied.)
When considering existing libraries for serialization this approach implies a performance overhead since the message must either be copied into the object provided by the serialization library (implying an additional copy) or custom code must be developed which serializes the message fields directly into the wire format (while bypassing the message class of the serialization library). Furthermore member-based access makes it problematic to add support for optional field.
On the other hand a method-based interface allows to implement arbitrary storage paradigms behind the API. The methods could either just access some private member variable directly or delegate the data storage to a separate entity which could e.g. be the serialization library specific data object. Commonly the methods can be inlined in languages like C++ so they don’t pose a significant performance hit but depending on the utilized storage the API might not expose mutable access to the fields which can imply an overhead when modifying data in-place.
Each serialization library has certain pros and cons depending on the scenario. The features of a serialization library can be extrinsic (exposed functionality through API, e.g. optional fields) or intrinsic (e.g. compactness of wire format). Conceptually only the intrinsic features can be exploited when a serialization library is used internally, e.g. behind a method-based message interface.
Support pluggable serialization library
The possible approaches to select the serialization library vary from a compile decision to being able to dynamically select the serialization library for each communication channel. Especially when a ROS graph spans multiple devices and networks the needs within one network are likely already different. Therefore a dynamic solution is preferred.
TODO add more benefits from whiteboard picture Serializatoin Pluggability
Possible message storage and serialization process
Pipeline A
The message used by the userland code stores its data directly. For each communication channel the message data is then copied into the serialization specific message representation. The serialization library will perform the serialization into the wire format from there.

Pipeline B
The message fields can be serialized directly into the wire format using custom code. While this avoids the extra data copy it requires a significant effort for implementing the custom serialization routine.

Pipeline C
The message delegates the data storage to an internally held storage backend, e.g. the serialization library specific message representation. Since the data is stored directly in the serialization library specific representation copying the data before serializing it is not necessary anymore.
This assumes that the API of the serialization library specific representation can be wrapped inside the ROS message API (see Technical Issues -> Variances in field types).
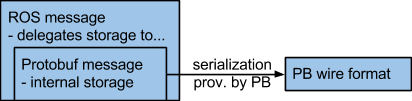
Select message storage
Under the assumption that we want to avoid implementing the serialization process from a custom message class into each supported serialization format (pipeline B) the process will either require one extra copy of the data (pipeline A) or the message must directly store its data in the specific message representation of the used serialization library (pipeline C).
For the later approach the decision can be made transparent to the userland code. Each publisher can act as a factory for message instances and create messages for the userland code which fit the currently used communication channels and their serialization format best. If multiple communication channels use different serialization formats the publisher should still choose one of them as the storage format for the created message instance to avoid at least one of the necessary storage conversions.
Binary compatibility of message revisions
When message objects are used in nodelets one problem is that two nodelets which run in the same process might have been linked against different definitions of a message. E.g. if we add optional fields to the message IDL one might contain the version without the optional field while the other does contain the extended version of the message.
The two different binary representations will break the ability to exchange them using a shared pointer.
This can be the case for any of the pipelines. In the case of pipeline A where only the ROS message is part of the nodelet library (the serialization specific code is only part of the nodelet manager) both revisions must be binary compatible. In the case of pipeline C some serialization libraries (e.g. Protobuf) are definitely not binary compatible when features like optional fields are being used (check this assumption).
Minimal code around existing libraries
Both pipeline A as well as C a possible to implement using a small layer around an external serialization libraries to adapt them to the message API and make them pluggable into the ROS message system.
Generate POD messages for embedded / real time use
Generate a special message class which acts as a POD which is mem-copyable as well as without any dynamic memory allocation. Although this can be done from any language, one particularly useful situation is for portable C99, for use in everything from microcontrollers to soft-core processors on FPGA’s, to screwed hard real-time environments.
For each set of max size constraints the message class would require a “mangled” name: e.g. in C99 Foo_10_20 would represent a message Foo where the two dynamic sized fields have max sizes of 10 and 20. For each type a default max size could be provided as well as each field could have a specific custom override in the message IDL. See https://github.com/ros2/prototypes/tree/master/c_fixed_msg for a prototype illustrating the concept.
Performance Evaluation
Member/method-based access and message copy vs. serialization
Serializing messages (small as well as big ones) is at least two orders of magnitude slower than accessing message fields and copying messages in memory. Therefore performing a message copy (from one data representation to the serialization library data representation) can be considered a neglectable overhead since the serialization is the clear performance bottleneck. The selection of one serialization library has a much higher impact on the performance. See https://github.com/ros2/prototypes/tree/master/c_fixed_msg for benchmark results of serialization libraries. Choosing pipeline A over pipeline B or C should therefore not impose any significant performance hit.
Member-based vs. method-based access (with storage in member variable)
As the results of produce_consume_struct and produce_consume_method show the performance difference is not measurable. Therefore a method-based interface is preferred as it allows future customizations (e.g. changing the way the data is stored internally).
Storage in message vs. storage in templated backend (both using method-based access)
As the results of produce_consume_method and produce_consume_backend_plain show the performance difference is again not measurable. Therefore a templated backend is preferred as it allows customizations (e.g. add value range validation, defer storage, implement thread safety, custom logging for debugging/introspection purposes) and enable to drop in custom storage backends (e.g. any message class of an existing serialization which suits our API).
Technical Issues
Variances in field types
Different serialization libraries specify different field type when e.g. generating C++ code for the messages. The major problem is the mapping between those types in an efficient manner. From a performance point of view the message interface should expose const references (especially to “big” fields). But those can only be mapped to the specific API of the serialization library if the types are exchangeable. But for example a byte array is represented differently in C++ in the various serialization libraries:
-
Protobuf:
- dynamic array<T>: RepeatedField<T> (STL-like interface)
- fixed array<T>: —
- binary/string: std::string
-
Thrift:
- dynamic array<T>: std::vector<T>
- fixed array<T>: —
- binary/string: std::string
-
ROS:
- array<T>: std::vector<T>
- fixed array<T, N>: boost::array<T, N>
- string: std::string
Furthermore the serialization library specific message API might not expose mutable access which could therefore not be provided by RO either when using pipeline C.
Preliminary Conclusion
Serialization Pipeline
Due to the mentioned problems and added complexity the pipeline C is not viable. Since the amount of time necessary for the memory copy before a serialization is orders of magnitudes smaller than the actual serialization pipeline A is selected for further prototyping. This still allows us to implement the optimization described as pipeline B for e.g. the default serialization library if need is.
Message Interface
Under the assumption that a method-based access is not significantly impacting the performance it is preferred over a member-based access in order to enable changing the storage backend in the future and enabling overriding it with a custom implementation.
Update
With the decision to build ROS 2 on top of DDS the Pipeline B will be used. The previous conclusion to switch from member to method based access has been revisited. Since we do not have the need to make the storage backend exchangeable anymore and we might prefer keeping the member based access of messages to keep it similar with ROS 1.