Intra-process Communications in ROS 2
Description of the current intra-process communication mechanism in ROS 2 and of its drawbacks. Design proposal for an improved implementation. Experimental results.
Authors: Alberto Soragna Juan Oxoby Dhiraj Goel
Date Written: 2020-03
Last Modified: 2020-03
Introduction
The subscriptions and publications mechanisms in ROS 2 fall in two categories:
- intra-process: messages are sent from a publisher to subscriptions via in-process memory.
- inter-process: messages are sent via the underlying ROS 2 middleware layer. The specifics of how this happens depend on the chosen middleware implementation and may involve serialization steps.
This design document presents a new implementation for the intra-process communication.
Motivations for a new implementation
Even if ROS 2 supports intra-process communication, the implementation of this mechanism has still much space for improvement. Until ROS 2 Crystal, major performance issues and the lack of support for shared pointer messages were preventing the use of this feature in real applications.
With the ROS 2 Dashing release, most of these issues have been addressed and the intra-process communication behavior has improved greatly (see ticket).
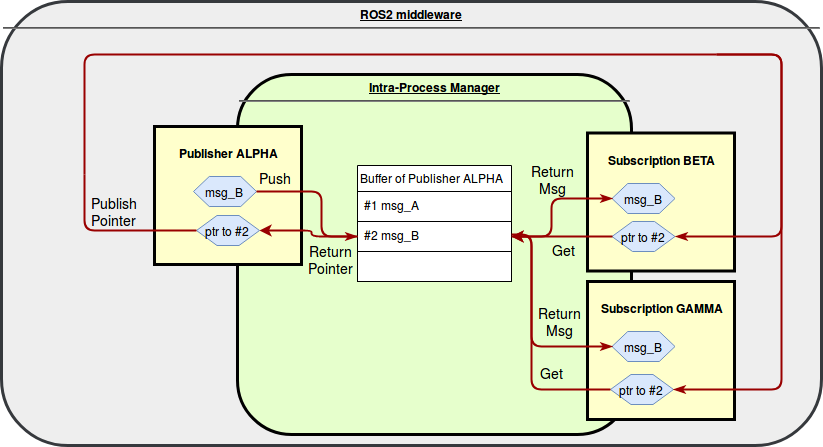
The current implementation is based on the creation of a ring buffer for each Publisher and on the publication of meta-messages through the middleware layer.
When a Publisher has to publish intra-process, it will pass the message to the IntraProcessManager.
Here the message will be stored in the ring buffer associated with the Publisher.
In order to extract a message from the IntraProcessManager two pieces of information are needed: the id of the Publisher (in order to select the correct ring buffer) and the position of the message within its ring buffer.
A meta-message with this information is created and sent through the ROS 2 middleware to all the Subscriptions, which can then retrieve the original message from the IntraProcessManager.
Several shortcomings of the current implementation are listed below.
Incomplete Quality of Service support
The current implementation can’t be used when the QoS durability value is set to Transient Local.
The current implementation does not enforce the depth of the QoS history in a correct way.
The reason is that there is a single ring buffer per Publisher and its size is equal to the depth of the Publisher’s history.
A Publisher stores a message in the ring buffer and then it sends a meta-message to allow a Subscription to retrieve it.
The Subscription correctly stores meta-messages up to the number indicated by its depth of the history, but, depending on the frequency at which messages are published and callbacks are triggered, it may happen that a meta-message processed from the Subscription does not correspond anymore to a valid message in the ring buffer, because it has been already overwritten.
This results in the loss of the message and it is also a difference in behavior between intra and inter-process communication, since, with the latter, the message would have been received.
Moreover, even if the use of meta-messages allows to deleagate the enforcement of other QoS settings to the RMW layer, every time a message is added to the ring buffer the IntraProcessManager has to compute how many Subscriptions will need it.
This potentially breaks the advantage of having the meta-messages.
For example, the IntraProcessManager has to take into account that potentially all the known Subscriptions will take the message, regardless of their reliability QoS.
If a Publisher or a Subscription are best-effort, they may not receive the meta-message thus preventing the IntraProcessManager from releasing the memory in the buffer.
More details here.
TODO: take into account also new QoS: Deadline, Liveliness and Lifespan reference.
Dependent on the RMW
The current implementation of intra-process communication has to send meta-messages from the Publisher to the Subscriptions.
This is done using the rmw_publish function, the implementation of which depends on the chosen middleware.
This results in the performance of a ROS 2 application with intra-process communication enabled being heavily dependent on the chosen RMW implementation.
Given the fact that these meta-messages have only to be received from entities within the same process, there is space for optimizing how they are transmitted by each RMW. However, at the moment none of the supported RMW is actively tackling this issue. This results in that the performance of a single process ROS 2 application with intra-process communication enabled are still worst than what you could expect from a non-ROS application sharing memory between its components.
In the following some experimental evidences are quickly presented.
Memory requirement
When a Node creates a Publisher or a Subscription to a topic /MyTopic, it will also create an additional one to the topic /MyTopic/_intra.
The second topic is the one where meta-messages travel.
Our experimental results show that creating a Publisher or a Subscription has a non-negligible memory cost.
This is particularly true for the default RMW implementation, Fast-RTPS, where the memory requirement increases almost expontentially with the number of participants and entities.
Latency and CPU utilization
Publishing a meta-message has the same overhead as that of publishing a small inter-process message.
However, comparing the publication/reception of an intra and an inter-process message, the former requires several additional operations: it has to store the message in the ring buffer, monitor the number of Subscriptions, and extract the message.
The result is that from the latency and CPU utilization point of view, it is convenient to use intra-process communication only when the message size is at least 5KB.
Problems when both inter and intra-process communication are needed
Currently, ROS 2 does not provide any API for making nodes or Publisher and Subscription to ignore each other.
This feature would be useful when both inter and intra-process communication are needed.
The reason is that the current implementation of the ROS 2 middleware will try to deliver inter-process messages also to the nodes within the same process of the Publisher, even if they should have received an intra-process message.
Note that these messages will be discarded, but they will still cause an overhead.
The DDS specification provides ways for potentially fixing this problem, i.e. with the ignore_participant, ignore_publication and ignore_subscriptionoperations.
Each of these can be used to ignore a remote participant or entity, allowing to behave as that remote participant did not exist.
The current intra-process communication uses meta-messages that are sent through the RMW between nodes in the same process.
This has two consequences: first it does not allow to directly “ignore” participants in the same process, because they still have to communicate in order to send and receive meta-messages, thus requiring a more fine-grained control ignoring specific Publishers and Subscriptions.
Moreover, the meta-messages could be delivered also to nodes in different processes if they have intra-process communication enabled. As before, the messages would be discarded immediately after being received, but they would still affect the performances. The overhead caused by the additional publication of meta-messages can be potentially reduced by appending to the intra-process topic names a process specific identifier.
Proposed implementation
Overview
The new proposal for intra-process communication addresses the issues previously mentioned. It has been designed with performance in mind, so it avoids any communication through the middleware between nodes in the same process.
Consider a simple scenario, consisting of Publishers and Subscriptions all in the same process and with the durability QoS set to volatile.
The proposed implementation creates one buffer per Subscription.
When a message is published to a topic, its Publisher pushes the message into the buffer of each of the Subscriptions related to that topic and raises a notification, waking up the executor.
The executor can then pop the message from the buffer and trigger the callback of the Subscription.
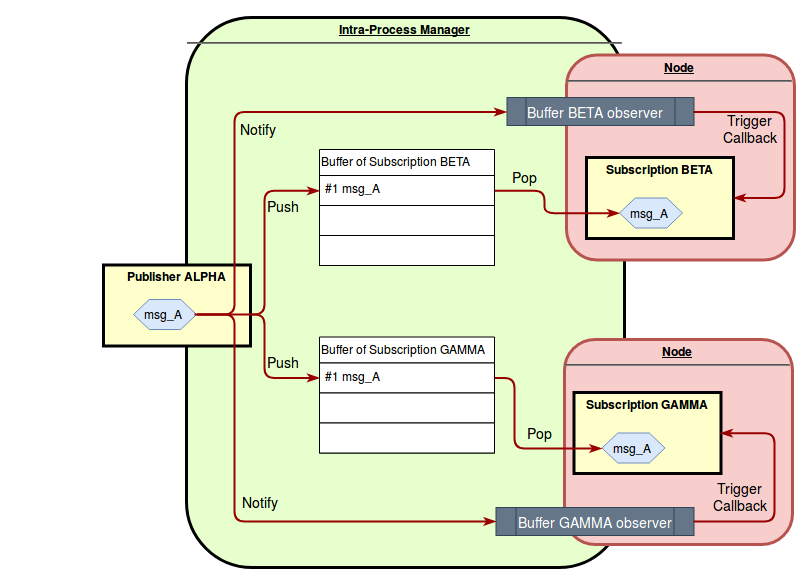
The choice of having independent buffers for each Subscription leads to the following advantages:
- It is easy to support different QoS for each
Subscription, while, at the same time, simplifying the implementation. - Multiple
Subscriptions can extract messages from their own buffer in parallel without blocking each other, thus providing higher throughput.
The only drawback is that the system is not reusing as much resources as possible, compared to sharing buffers between entities. However, from a practical point of view, the memory overhead caused by the proposed implementation with respect to the current one, will always be only a tiny delta compared to the overall memory usage of the application.
There are three possible data-types that can be stored in the buffer:
MessageTshared_ptr<const MessageT>unique_ptr<MessageT>
The choice of the buffer data-type is controlled through an additional field in the SubscriptionOptions.
The default value for this option is denominated CallbackDefault, which corresponds to selecting the type between shared_ptr<constMessageT> and unique_ptr<MessageT> that better fits with its callback type.
This is deduced looking at the output of AnySubscriptionCallback::use_take_shared_method().
If the history QoS is set to keep all, the buffers are dynamically adjusted in size up to the maximum resource limits specified by the underlying middleware.
On the other hand, if the history QoS is set to keep last, the buffers have a size equal to the depth of the history and they act as ring buffers (overwriting the oldest data when trying to push while its full).
Note that in case of publishers with keep all and reliable communication, the behavior can be different from the one of inter-process communication.
In the inter-process case, the middlewares use buffers in both publisher and subscription.
If the subscription queue is full, the publisher one would start to fill and then finally the publish call would block when that queue is full.
Since the intra-process communication uses a single queue on the subscription, this behavior can’t be exactly emulated.
Buffers are not only used in Subscriptions but also in each Publisher with a durability QoS of type transient local.
The data-type stored in the Publisher buffer is always shared_ptr<const MessageT>.
A new class derived from rclcpp::Waitable is defined, which is named SubscriptionIntraProcessWaitable.
An object of this type is created by each Subscription with intra-process communication enabled and it is used to notify the Subscription that a new message has been pushed into its ring buffer and that it needs to be processed.
The IntraProcessManager class stores information about each Publisher and each Subscription, together with pointers to these structures.
This allows the system to know which entities can communicate with each other and to have access to methods for pushing data into the buffers.
The decision whether to publish inter-process, intra-process or both is made every time the Publisher::publish() method is called.
For example, if the NodeOptions::use_intra_process_comms_ is enabled and all the known Subscriptions are in the same process, then the message is only published intra-process.
This remains identical to the current implementation.
Creating a publisher
- User calls
Node::create_publisher<MessageT>(...). - This boils down to
NodeTopics::create_publisher(...), where aPublisheris created through the factory. - Here, if intra-process communication is enabled, eventual intra-process related variables are initialized through the
Publisher::SetupIntraProcess(...)method. - Then the
IntraProcessManageris notified about the existence of the newPublisherthrough the methodIntraProcessManager::add_publisher(PublisherBase::SharedPtr publisher, PublisherOptions options). IntraProcessManager::add_publisher(...)stores thePublisherinformation in an internal structure of typePublisherInfo. The structure contains information about thePublisher, such as its QoS and its topic name, and a weak pointer for thePublisherobject. Anuint64_t pub_idunique within therclcpp::Contextis assigned to thePublisher. TheIntraProcessManagercontains astd::map<uint64_t, PublisherInfo>object where it is possible to retrieve thePublisherInfoof a specificPublishergiven its id. The function returns thepub_id, that is stored within thePublisher.
If the Publisher QoS is set to transient local, then the Publisher::SetupIntraProcess(...) method will also create a ring buffer of the size specified by the depth from the QoS.
Creating a subscription
- User calls
Node::create_subscription<MessageT>(...). - This boils down to
NodeTopics::create_subscription(...), where aSubscriptionis created through the factory. - Here, if intra-process communication is enabled, intra-process related variables are initialized through the
Subscription::SetupIntraProcess(...)method. The most relevant ones being the ring buffer and the waitable object. - Then the
IntraProcessManageris notified about the existence of the newSubscriptionthrough the methodIntraProcessManager::add_subscription(SubscriptionBase::SharedPtr subscription, SubscriptionOptions options). IntraProcessManager::add_subscription(...)stores theSubscriptioninformation in an internal structure of typeSubscriptionInfo. The structure contains information about theSubscription, such as its QoS, its topic name and the type of its callback, and a weak pointer for theSubscriptionobject. Anuint64_t sub_idunique within therclcpp::Contextis assigned to theSubscription. TheIntraProcessManagercontains astd::map<uint64_t, SubscriptionInfo>object where it is possible to retrieve theSubscriptionInfoof a specificSubscriptiongiven its id. There is also an additional structurestd::map<uint64_t, std::pair<std::set<uint64_t>, std::set<uint64_t>>>. The key of the map is the unique id of aPublisherand the value is a pair of sets of ids. These sets contain the ids of theSubscriptions that can communicate with thePublisher. We have two different sets because we want to differentiate theSubscriptions depending on whether they request ownership of the received messages or not (note that this decision is done looking at their buffer, since thePublisherdoes not have to interact with theSubscriptioncallback).- The
SubscriptionIntraProcessWaitableobject is added to the list of Waitable interfaces of the node throughnode_interfaces::NodeWaitablesInterface::add_waitable(...). It is added to the same callback group used for the standard inter-process communication of that topic.
Publishing only intra-process
Publishing unique_ptr
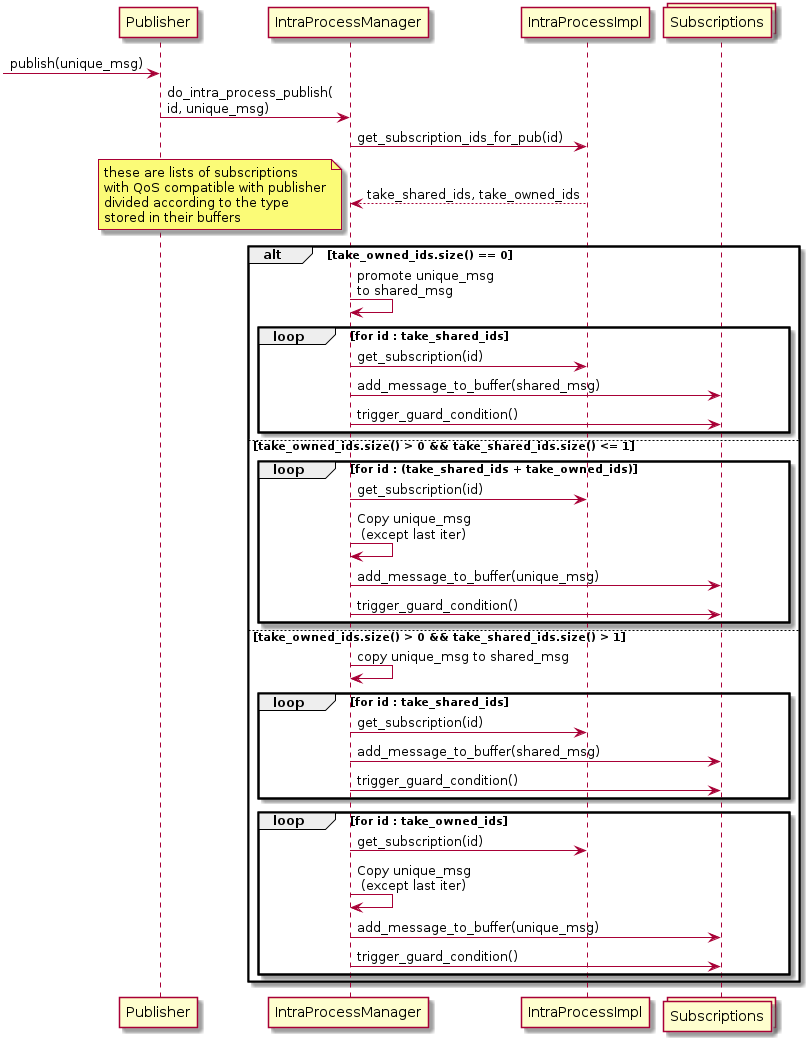
- User calls
Publisher::publish(std::unique_ptr<MessageT> msg). Publisher::publish(std::unique_ptr<MessageT> msg)callsIntraProcessManager::do_intra_process_publish(uint64_t pub_id, std::unique_ptr<MessageT> msg).IntraProcessManager::do_intra_process_publish(...)uses theuint64_t pub_idto callIntraProcessManager::get_subscription_ids_for_pub(uint64_t pub_id). This returns the ids corresponding toSubscriptions that have a QoS compatible for receiving the message. These ids are divided into two sublists, according to the data-type that is stored in the buffer of eachSusbscription: requesting ownership (unique_ptr<MessageT>) or accepting shared (shared_ptr<MessageT>, but alsoMessageTsince it will copy data in any case).- The message is “added” to the ring buffer of all the items in the lists.
The
rcl_guard_condition_tmember ofSubscriptionIntraProcessWaitableof eachSubscriptionis triggered (this wakes uprclcpp::spin).
The way in which the std::unique_ptr<MessageT> message is “added” to a buffer, depends on the type of the buffer.
BufferT = unique_ptr<MessageT>The buffer receives a copy ofMessageTand has ownership on it; for the last buffer, a copy is not necessary as ownership can be transferred.BufferT = shared_ptr<const MessageT>Every buffer receives a shared pointer of the sameMessageT; no copies are required.BufferT = MessageTA copy of the message is added to every buffer.
Publishing other message types
The Publisher::publish(...) method is overloaded to support different message types:
unique_ptr<MessageT>MessageT &MessageT*const shared_ptr<const MessageT>
The last two of them are actually deprecated since ROS 2 Dashing.
All these methods are unchanged with respect to the current implementation: they end up creating a unique_ptr and calling the Publisher::publish(std::unique_ptr<MessageT> msg) described above.
Receiving intra-process messages
As previously described, whenever messages are added to the ring buffer of a Subscription, a condition variable specific to the Subscription is triggered.
This condition variable has been added to the Node waitset so it is being monitored by the rclcpp::spin.
Remember that the SubscriptionIntraProcessWaitable object has access to the ring buffer and to the callback function pointer of its related Subscription.
- The guard condition linked with the
SubscriptionIntraProcessWaitableobject awakesrclcpp::spin. - The
SubscriptionIntraProcessWaitable::is_ready()condition is checked. This has to ensure that the ring buffer is not empty. - The
SubscriptionIntraProcessWaitable::execute()function is triggered. Here the first message is extracted from the buffer and then theSubscriptionIntraProcessWaitablecalls theAnySubscriptionCallback::dispatch_intra_process(...)method. There are different implementations for this method, depending on the data-type stored in the buffer. - The
AnySubscriptionCallback::dispatch_intra_process(...)method triggers the associated callback. Note that in this step, if the type of the buffer is a smart pointer one, no message copies occurr, as ownership has been already taken into account when pushing a message into the queue.
Publishing intra and inter-process
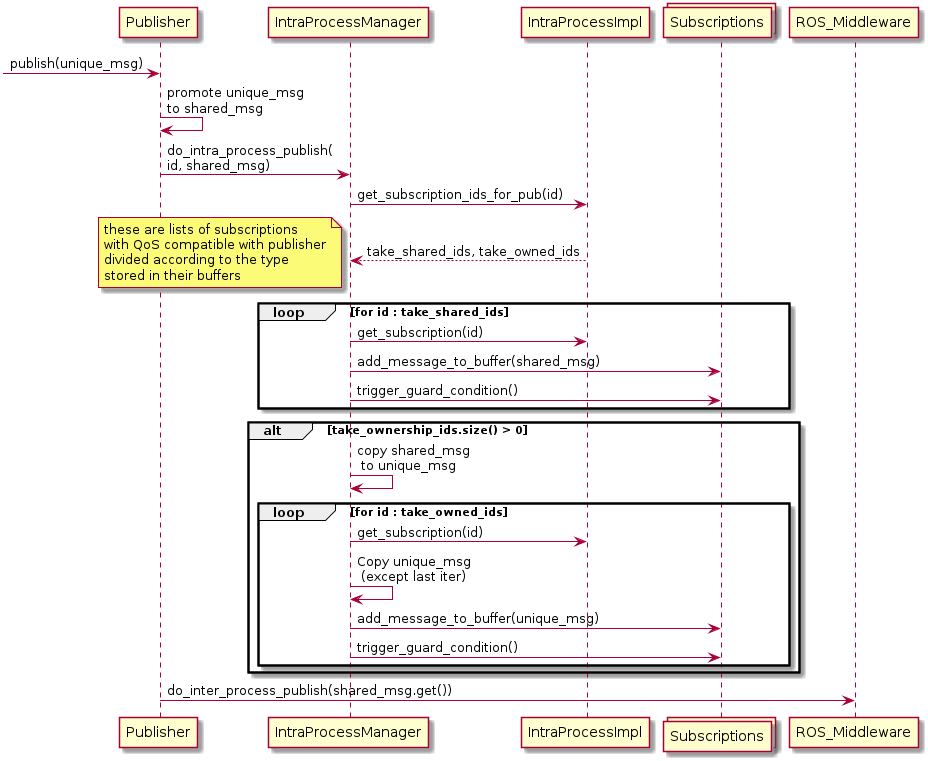
- User calls
Publisher::publish(std::unique_ptr<MessageT> msg). - The message is moved into a shared pointer
std::shared_ptr<MessageT> shared_msg = std::move(msg). Publisher::publish(std::unique_ptr<MessageT> msg)callsIntraProcessManager::do_intra_process_publish(uint64_t pub_id, std::shared_ptr<MessageT> shared_msg).
The following steps are identical to steps 3, 4, and 5 applied when publishing only intra-process.
IntraProcessManager::do_intra_process_publish(...)uses theuint64_t pub_idto callIntraProcessManager::get_subscription_ids_for_pub(uint64_t pub_id). Then it callsIntraProcessManager::find_matching_subscriptions(PublisherInfo pub_info). This returns the ids corresponding toSubscriptions that have a QoS compatible for receiving the message. These ids are divided into two sublists, according to the data-type that is stored in the buffer of eachSusbscription: requesting ownership (unique_ptr<MessageT>) or accepting shared (shared_ptr<MessageT>, but alsoMessageTsince it will copy data in any case).- The message is “added” to the ring buffer of all the items in the list.
The
rcl_guard_condition_tmember ofSubscriptionIntraProcessWaitableof eachSubscriptionis triggered (this wakes uprclcpp::spin).
After the intra-process publication, the inter-process one takes place.
Publisher::publish(std::unique_ptr<MessageT> msg)callsPublisher::do_inter_process_publish(const MessageT & inter_process_msg), whereMessageT inter_process_msg = *shared_msg.
The difference from the previous case is that here a std::shared_ptr<const MessageT> is being “added” to the buffers.
Note that this std::shared_ptr has been just created from a std::unique_ptr and it is only used by the IntraProcessManager and by the RMW, while the user application has no access to it.
BufferT = unique_ptr<MessageT>The buffer receives a copy ofMessageTand has ownership on it.BufferT = shared_ptr<const MessageT>Every buffer receives a shared pointer of the sameMessageT, so no copies are required.BufferT = MessageTA copy of the message is added to every buffer.
The difference with publishing a unique_ptr is that here it is not possible to save a copy.
If you move the ownership of the published message to one of the Subscription (so potentially saving a copy as done in the previous case), you will need to create a new copy of the message for inter-process publication.
QoS features
The proposed implementation can handle all the different QoS.
- If the history is set to
keep_last, then the depth of the history corresponds to the size of the ring buffer. On the other hand, if the history is set tokeep_all, the buffer becomes a standard FIFO queue with an unbounded size. - The reliability is only checked by the
IntraProcessManagerin order to understand if aPublisherand aSubscriptionare compatible. The use of buffers ensures that all the messages are delivered without the need to resend them. Thus, both options,reliableandbest-effort, are satisfied. - The durability QoS is used to understand if a
Publisherand aSubscriptionare compatible. How this QoS is handled is described in details in the following paragraph.
Handling Transient Local
If the Publisher durability is set to transient_local an additional buffer on the Publisher side is used to store the sent intra-process messages.
Late-joiner Subscriptions will have to extract messages from this buffer once they are added to the IntraProcessManager.
In this case the IntraProcessManager has to check if the recently created Subscription is a late-joiner, and, if it is, it has to retrieve messages from the Transient Local Publishers.
- Call
IntraProcessManager::find_matching_publishers(SubscriptionInfo sub_info)that returns a list of storedPublisherInfothat have a QoS compatible for sending messages to this newSubscription. These will be allTransient LocalPublishers, so they have a ring buffer. - Copy messages from all the ring buffers found into the ring buffer of the new
Subscription. TODO: are there any constraints on the order in which old messages have to be retrieved? (i.e. 1 publisher at the time; all the firsts of each publisher, then all the seconds …). - If at least 1 message was present, trigger the
rcl_guard_condition_tmember of theSubscriptionIntraProcessWaitableassociated with the newSubscription.
However, this is not enough as it does not allow to handle the scenario in which a transient local Publisher has only intra-process Subscriptions when it is created, but, eventually, a transient local Subscription in a different process joins.
Initially, published messages are not passed to the middleware, since all the Subscriptions are in the same process.
This means that the middleware is not able to store old messages for eventual late-joiners.
The solution to this issue consists in always publishing both intra and inter-process when a Publisher has transient local durability.
For this reason, when transient local is enabled, the do_intra_process_publish(...) function will always process a shared pointer.
This allows us to add the logic for storing the published messages into the buffers only in one of the two do_intra_process_publish(...) cases and also it allows to use buffers that have only to store shared pointers.
Number of message copies
In the previous sections, it has been briefly described how a message can be added to a buffer, i.e. if it is necessary to copy it or not.
Here some details about how this proposal adresses some more complex cases.
As previously stated, regardless of the data-type published by the user, the flow always goes towards Publisher::publish(std::unique_ptr<MessageT> msg).
The std::unique_ptr<MessageT> msg is passed to the IntraProcessManger that decides how to add this message to the buffers.
The decision is taken looking at the number and the type, i.e. if they want ownership on messages or not, of the Subscriptions.
If all the Subscriptions want ownership of the message, then a total of N-1 copies of the message are required, where N is the number of Subscriptions.
The last one will receive ownership of the published message, thus saving a copy.
If none of the Subscriptions want ownership of the message, 0 copies are required.
It is possible to convert the message into a std::shared_ptr<MessageT> msg and to add it to every buffer.
If there is 1 Subscription that does not want ownership while the others want it, the situation is equivalent to the case of everyone requesting ownership:N-1 copies of the message are required.
As before the last Subscription will receive ownership.
If there is more than 1 Subscription that do not want ownership while the others want it, a total of M copies of the message are required, where M is the number of Subscriptions that want ownership.
1 copy will be shared among all the Subscriptions that do not want ownership, while M-1 copies are for the others.
As in the current implementation, if both inter and intra-process communication are needed, the std::unique_ptr<MessageT> msg will be converted into a std::shared_ptr<MessageT> msg and passed respectively to the do_intra_process_publish and do_inter_process_publish functions.
A copy of the message will be given to all the Subscriptions requesting ownership, while the others can copy the published shared pointer.
The following tables show a recap of when the proposed implementation has to create a new copy of a message.
The notation @ indicates a memory address where the message is stored, different memory addresses correspond to different copies of the message.
Publishing UniquePtr
| publish<T> | BufferT | Results |
|---|---|---|
| unique_ptr<MsgT> @1 | unique_ptr<MsgT> | @1 |
| unique_ptr<MsgT> @1 | unique_ptr<MsgT> unique_ptr<MsgT> |
@1 @2 |
| unique_ptr<MsgT> @1 | shared_ptr<MsgT> | @1 |
| unique_ptr<MsgT> @1 | shared_ptr<MsgT> shared_ptr<MsgT> |
@1 @1 |
| unique_ptr<MsgT> @1 | unique_ptr<MsgT> shared_ptr<MsgT> |
@1 @2 |
| unique_ptr<MsgT> @1 | unique_ptr<MsgT> shared_ptr<MsgT> shared_ptr<MsgT> |
@1 @2 @2 |
| unique_ptr<MsgT> @1 | unique_ptr<MsgT> unique_ptr<MsgT> shared_ptr<MsgT> shared_ptr<MsgT> |
@1 @2 @3 @3 |
Publishing SharedPtr
| publish<T> | BufferT | Results |
|---|---|---|
| shared_ptr<MsgT> @1 | unique_ptr<MsgT> | @2 |
| shared_ptr<MsgT> @1 | unique_ptr<MsgT> unique_ptr<MsgT> |
@2 @3 |
| shared_ptr<MsgT> @1 | shared_ptr<MsgT> | @1 |
| shared_ptr<MsgT> @1 | shared_ptr<MsgT> shared_ptr<MsgT> |
@1 @1 |
| shared_ptr<MsgT> @1 | unique_ptr<MsgT> shared_ptr<MsgT> |
@2 @1 |
| shared_ptr<MsgT> @1 | unique_ptr<MsgT> shared_ptr<MsgT> shared_ptr<MsgT> |
@2 @1 @1 |
| shared_ptr<MsgT> @1 | unique_ptr<MsgT> unique_ptr<MsgT> shared_ptr<MsgT> shared_ptr<MsgT> |
@2 @3 @1 @1 |
The possibility of setting the data-type stored in each buffer becomes helpful when dealing with more particular scenarios.
Considering a scenario with N Subscriptions all taking a unique pointer.
If the Subscriptions don’t actually take the message (e.g. they are busy and the message is being overwritten due to QoS settings) the default buffer type (unique_ptr since the callbacks require ownership) would result in the copy taking place anyway.
By setting the buffer type to shared_ptr, no copies are needed when the Publisher pushes messages into the buffers.
Eventually, the Subscriptions will copy the data only when they are ready to process it.
On the other hand, if the published data are very small, it can be advantageous to do not use C++ smart pointers, but to directly store the data into the buffers.
In all this situations, the number of copies is always smaller or equal than the one required for the current intra-process implementation.
However, there is a particular scenario where having multiple buffers makes much more difficult saving a copy.
There are two Subscriptions, one taking a shared pointer and the other taking a unique pointer.
With a more centralized system, if the first Subscription requests its shared pointer and then releases it before the second Subscription takes the message, it is potentially possible to optimize the system to manage this situation without requiring any copy.
On the other hand, the proposed implementation will immediately create one copy of the message for the Subscription requiring ownership.
Even in case of using a shared_ptr buffer as previously described, it becomes more difficult to ensure that the other Subscription is not using the pointer anymore.
Where are these copies performed?
The IntraProcessManger::do_intra_process_publish(...) function knows whether the intra-process buffer of each Subscription requires ownership or not.
For this reason it can perform the minimum number of copies required by looking at the total number of Subscriptions and their types.
The buffer does not perform any copy when receiving a message, but directly stores it.
When extracting a message from the buffer, the Subscription can require any particular data-type.
The intra-process buffer will perform a copy of the message whenever necessary, for example in the previously described cases where the data-type stored in the buffer is different from the callback one.
Perfomance evaluation
The implementation of the presented new intra-process communication mechanism is hosted on GitHub here.
This section contains experimental results obtained comparing the current intra-process communication implementation with an initial implementation of the proposed one. The tests span multiple ROS 2 applications and use-cases and have been validated on different machines.
All the following experiments have been run using the ROS 2 Dashing and with -O2 optimization enabled.
colcon build --cmake-args -DCMAKE_CXX_FLAGS="-O2" -DCMAKE_C_FLAGS="-O2"
The first test has been carried out using the intra_process_demo package contained in the ROS 2 demos repository.
A first application, called image_pipeline_all_in_one, is made of 3 nodes, where the fist one publishes a unique_ptr<Image> message.
A second node subscribes to the topic and republishes the image after modifying it on a new topic.
A third node subscribes to to this last topic.
Also a variant of the application has been tested: it’s image_pipeline_with_two_image_view, where there are 2 consumers at the end of the pipeline.
In these tests the latency is computed as the total pipeline duration, i.e. the time from when the first node publishes the image to when the last node receives it.
The CPU usage and the latency have been obtained from top command and averaged over the experiment duration.
Performance evaluation on a laptop computer with Intel i7-6600U CPU @ 2.60GHz.
| ROS 2 system | IPC | RMW | Latency [us] | CPU [%] | RAM [Mb] |
|---|---|---|---|---|---|
| image_pipeline_all_in_one | off | Fast-RTPS | 1800 | 23 | 90 |
| image_pipeline_all_in_one | standard | Fast-RTPS | 920 | 20 | 90 |
| image_pipeline_all_in_one | new | Fast-RTPS | 350 | 15 | 90 |
| image_pipeline_with_two_image_view | off | Fast-RTPS | 2900 | 24 | 94 |
| image_pipeline_with_two_image_view | standard | Fast-RTPS | 2000 | 20 | 95 |
| image_pipeline_with_two_image_view | new | Fast-RTPS | 1400 | 16 | 94 |
From this simple experiment is immediately possible to see the improvement in the latency when using the proposed intra-process communication. However, an even bigger improvement is present when analyzing the results from more complex applications.
The next results have been obtained running the iRobot benchmark application. This allows the user to specify the topology of a ROS 2 graph that will be entirely run in a single process.
The application has been run with the topologies Sierra Nevada and Mont Blanc. Sierra Nevada is a 10-node topology and it contains 10 publishers and 13 subscriptions. One topic has a message size of 10KB, while all the others have message sizes between 10 and 100 bytes.
Mont Blanc is a bigger 20-node topology, containing 23 publishers and 35 subscriptions. Two topics have a message size of 250KB, three topics have message sizes between 1KB and 25KB, and the rest of the topics have message sizes smaller than 1KB.
A detailed description and the source code for these application and topologies can be found here.
Note that, differently from the previous experiment where the ownership of the messages was moved from the publisher to the subscription, here nodes use const std::shared_ptr<const MessageT> messages for the callbacks.
Performance evaluation on a laptop computer with Intel i7-6600U CPU @ 2.60GHz.
| ROS 2 system | IPC | RMW | Latency [us] | CPU [%] | RAM [Mb] |
|---|---|---|---|---|---|
| Sierra Nevada | off | Fast-RTPS | 600 | 14 | 63 |
| Sierra Nevada | standard | Fast-RTPS | 650 | 16 | 73->79 |
| Sierra Nevada | new | Fast-RTPS | 140 | 8 | 63 |
| Mont Blanc | off | Fast-RTPS | 1050 | 22 | 180 |
| Mont Blanc | standard | Fast-RTPS | 750 | 18 | 213->220 |
| Mont Blanc | new | Fast-RTPS | 160 | 8 | 180 |
A similar behavior can be observed also running the application on resource constrained platforms. The following results have been obtained on a RaspberryPi 2.
| ROS 2 system | IPC | RMW | Latency [us] | CPU [%] | RAM [Mb] |
|---|---|---|---|---|---|
| Sierra Nevada | off | Fast-RTPS | 800 | 18 | 47 |
| Sierra Nevada | standard | Fast-RTPS | 725 | 20 | 54->58 |
| Sierra Nevada | new | Fast-RTPS | 170 | 10 | 47 |
| Mont Blanc | off | Fast-RTPS | 1500 | 30 | 130 |
| Mont Blanc | standard | Fast-RTPS | 950 | 26 | 154->159 |
| Mont Blanc | new | Fast-RTPS | 220 | 14 | 130 |
For what concerns latency and CPU usage, Sierra Nevada behaves almost the same regardless if standard IPC is enabled or not. This is due to the fact that most of its messages are very small in size. On the other hand, there are noticeable improvements in Mont Blanc, where several messages of non-negligible size are used.
From the memory point of view, there is an almost constant increase in the utilization during the execution of the program when standard intra-process communication mechanism is used. Since the experiments have been run for 120 seconds, there is an increase of approximately 60KB per second. However, even considering the initial memory usage, it is possible to see how it is affected from the presence of the additional publishers and subscriptions needed for intra-process communication. There is a difference of 10MB in Sierra Nevada and of 33MB in Mont Blanc between standard intra-process communication on and off.
The last experiment show how the current implementation performs in the case that both intra and inter-process communication are needed.
The test consists of running Sierra Nevada on RaspberryPi 2, and, in a separate desktop machine, a single node subscribing to all the available topics coming from Sierra Nevada.
This use-case is common when using tools such as rosbag or rviz.
| ROS 2 system | IPC | RMW | Latency [us] | CPU [%] | RAM [Mb] |
|---|---|---|---|---|---|
| Sierra Nevada + debug node | off | Fast-RTPS | 800 | 22 | 50 |
| Sierra Nevada + debug node | standard | Fast-RTPS | 1100 | 35 | 60->65 |
| Sierra Nevada + debug node | new | Fast-RTPS | 180 | 15 | 32 |
These results show that if there is at least one node in a different process, with the current implementation it is better to keep intra-process communication disabled. The proposed implementation does not require the ROS 2 middleware when publishing intra-process. This allows to easily remove the connections between nodes in the same process when it is required to publish also inter process, potentially resulting in a very small overhead with respect to the only intra-process case.
Open Issues
There are some open issues that are not addressed neither on the current implementation nor on the proposed one.
- The proposal does not take into account the problem of having a queue with twice the size when both inter and intra-process communication are used.
A
Publisheror aSubscriptionwith a history depth of 10 will be able to store up to 20 messages without processing them (10 intra-process and 10 inter-process). This issue is also present in the current implementation, since eachSubscriptionis doubled.